
Amazon Redshift is a fully managed cloud data warehouse from AWS designed for large-scale analytics workloads. It uses columnar storage, parallel query execution, and automatic compression to deliver fast query performance over structured data at scale. Redshift integrates natively with the broader AWS ecosystem and supports standard SQL, making it a common choice for centralizing and querying business data from multiple sources. Connecting Amazon Redshift to Databox lets you pull data directly from your warehouse, build custom metrics using SQL queries, and visualize results alongside data from your other connected tools.
If you've already established a connection, you can reuse it to add new data sources to your Databox account.
Databox only reads data from your warehouse — it never writes to it. Create a dedicated Redshift user with SELECT-only privileges on the schemas and tables you want to expose. You can run these commands using a SQL client connected to your Redshift cluster, or via the Query editor in the AWS Management Console.
CREATE USER databox PASSWORD 'your_secure_password';
GRANT CONNECT ON DATABASE your_database TO databox;
GRANT USAGE ON SCHEMA public TO databox;
GRANT SELECT ON ALL TABLES IN SCHEMA public TO databox;
ALTER DEFAULT PRIVILEGES IN SCHEMA public GRANT SELECT ON TABLES TO databox;Replace your_database with the name of the database you want to connect, and your_secure_password with a strong password. If you need to expose tables in additional schemas, repeat the GRANT USAGE and GRANT SELECT statements for each schema.
By default, Redshift clusters are not accessible from outside their VPC. To allow Databox to reach your cluster, it must be configured as publicly accessible.
- In the AWS Management Console, go to Clusters and select your cluster.
- Click Actions > Modify.
- Under Network and security, set Publicly accessible to Yes.
- Click Save changes.
Redshift controls network access through VPC security groups. Add an inbound rule that permits TCP traffic on port 5439 from the Databox IP address.
- In the AWS Management Console, go to Clusters and select your cluster.
- Under the Properties tab, click the link to the VPC security group associated with the cluster.
- Select the security group, then click Edit inbound rules.
- Click Add rule and fill in:
- Type: Redshift
- Protocol: TCP
- Port range: 5439
- Source: Custom — enter
52.4.198.118/32
- Click Save rules.
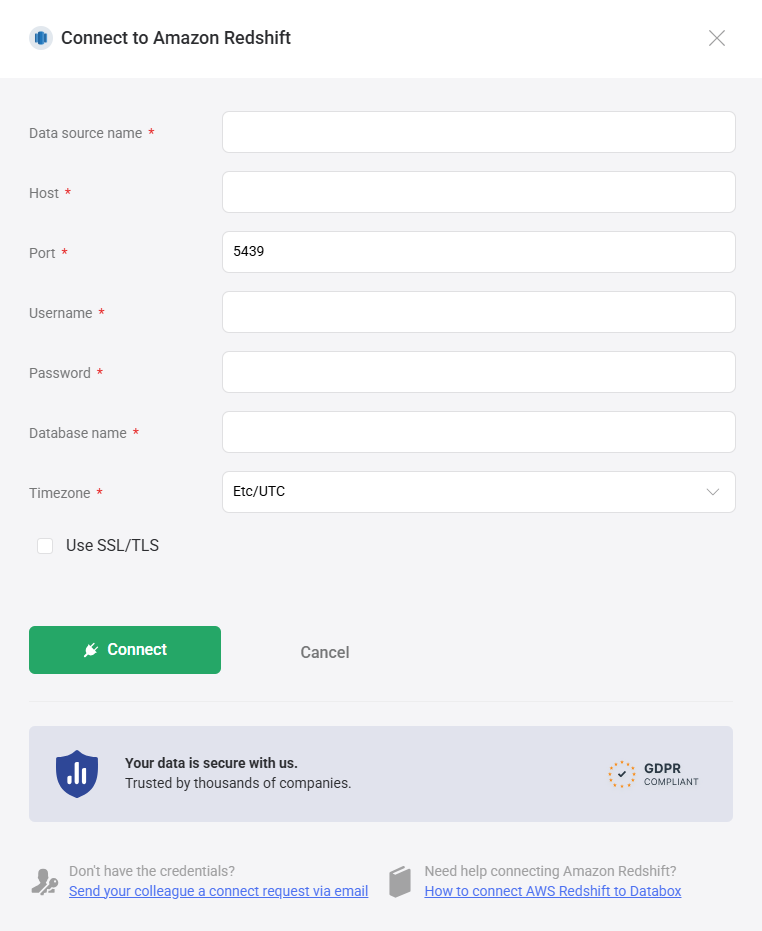
- In Databox, go to Data Sources > + New connection.
- Search for Amazon Redshift and click Connect.
- Fill in the connection form:
- Data source name — a label for this connection in Databox.
- Host — your Redshift cluster endpoint, found on the cluster's General information tab in the AWS Console under Endpoint (e.g.,
my-cluster.abc123.us-east-1.redshift.amazonaws.com). Do not include the port number that may appear at the end of the endpoint string. - Port — the port your Redshift cluster listens on. The default is
5439. - Username — the Redshift username created in Step 1.
- Password — the password for that user.
- Database name (optional) — the specific database to connect to. Leave blank to connect at the server level.
- Timezone — the time zone used to interpret date values in query results. Defaults to
Etc/UTC.
- Toggle Use SSL/TLS to enable encrypted connections.
- Click Connect.
The Amazon Redshift integration supports the creation of datasets, which allow you to define and shape the specific data you want to use for reporting in Databox. Datasets make it easier to focus on the most relevant information, enabling you to filter, visualize, and analyze metrics across projects, teams, and clients without writing complex queries each time.
- Select a table: Pick the appropriate schema within that database.
- Select columns: Browse and select the specific columns (fields) from your tables or views to include in your dataset. These columns define the structure and content of your dataset.
For more advanced use cases, you can write a custom SQL query instead of selecting columns manually. This allows you to:
- Join multiple tables
- Apply filters and aggregations
- Format or transform data before importing it into Databox
Your query must return a valid tabular result to be used as a dataset.
- Amazon Redshift documentation — Official AWS docs for Amazon Redshift, covering cluster creation, connectivity, user management, security, backups, and query optimization.
- Amazon Redshift database developer guide — SQL reference, user and group management, and schema design guidance for Redshift databases.
For comprehensive details on metrics, data availability, templates, specifications, usage guidelines, and other key information, refer to the resources listed below.



FAQ
Does Databox support IAM authentication for Redshift?
No. Databox connects using standard database username and password credentials. IAM authentication is not currently supported.
What should I do if Databox cannot connect to my Redshift cluster?
Check the following in order:
- Publicly accessible is set to Yes on the cluster (under Actions > Modify > Network and security).
- The VPC security group has an inbound rule allowing TCP on port
5439from52.4.198.118/32. - The VPC subnet has a route to an internet gateway (
0.0.0.0/0). - The Redshift user was created and has
CONNECTandSELECTprivileges on the target database and schema.
Where do I find my Redshift cluster endpoint?
In the AWS Management Console, go to Redshift > Clusters, select your cluster, and open the General information tab. The endpoint is listed under Endpoint and follows the format cluster-name.xxxxxxxxxxxx.region.redshift.amazonaws.com:5439. Enter only the hostname part (without :5439) in the Host field in Databox, and enter 5439 separately in the Port field.



