
Calculated columns let you create new values in your dataset by applying custom logic or transformations to your existing data. This is especially useful when you need to:
- Normalize or reformat values for comparison or visualization
- Combine multiple columns into a single result
- Apply conditional logic (e.g., flagging results based on thresholds)
- Perform mathematical operations that aren't available by default
Instead of modifying your source data, calculated columns give you a flexible way to enrich it — right inside the dataset editor.
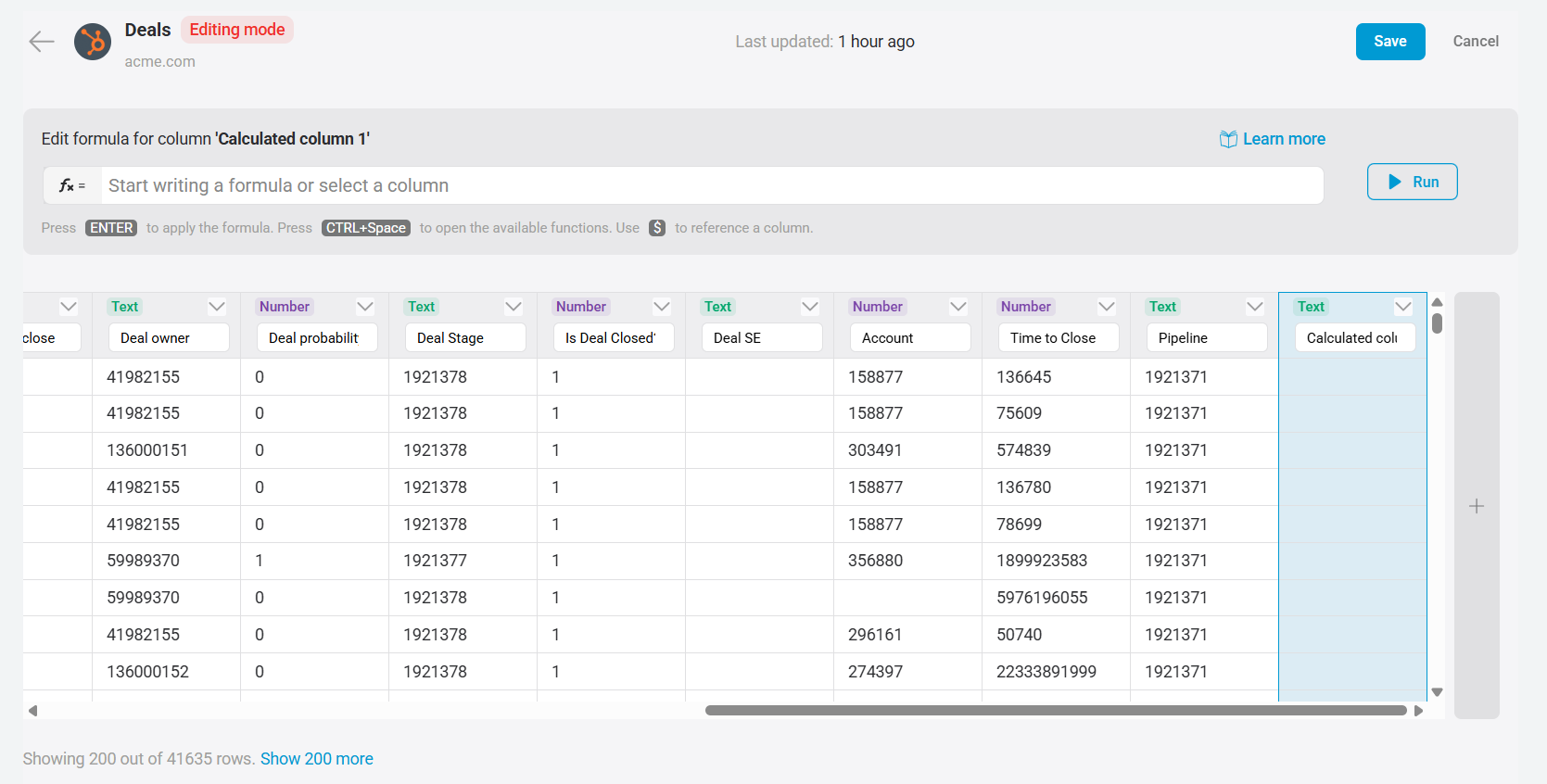
- Navigate to the Datasets page and find the dataset you want to update.
- Click the down arrow (
 ) next to the dataset name and select Edit data.
) next to the dataset name and select Edit data. - In the dataset editing mode, click the + bar at the far right of the table to open the formula input field above the dataset.
- Enter your formula using supported functions, operators, column references, and values.
- Click
 Run to preview how the new column will look across all rows.
Run to preview how the new column will look across all rows. - If everything looks good, click Save in the top right corner to apply your changes.
To speed up formula building and reduce the chance of errors, use the following keyboard shortcuts:
- Ctrl + Space — Opens a list of all supported functions you can use in formulas.
- $ — Displays a dropdown of available columns you can insert as parameters.
These shortcuts make it easier to build accurate formulas without needing to memorize every function or column name.
The formula field only accepts specific input types and supports formulas up to 10,000 characters. If your formula contains unsupported elements or syntax errors, an error message will be displayed and you'll need to correct the formula before you can run or save it.
Supported inputs include:
- Functions
- Operators
- Numeric values* (e.g.,
10,3.14) - Text values, enclosed in single quotes (e.g.,
'Completed') - Column references, using the $ symbol (e.g.,
$Status), and double quotes ($"Project-Name") if the column name includes spaces or special characters
* In dataset columns, logical values are automatically cast as numbers — true becomes 1, and false becomes 0
Any input outside of these types will be flagged as invalid.
To help you get started, all supported operators and functions are organized by category below.
Operators perform basic operations on values or expressions. You can think of them as the "glue" that connects, compares, or transforms values within formulas.
Below is a quick overview of the different types of operators. Click a category below to jump to its full explanation.



These are basic math symbols used to calculate values.
 If formulas are recipes, numeric operators are the math utensils you use to prepare your ingredients.
If formulas are recipes, numeric operators are the math utensils you use to prepare your ingredients.
| Operator | Description | Example | Result |
|---|---|---|---|
+ | Addition | 2 + 3 | 5 |
- | Subtraction | 2 - 3 | -1 |
* | Multiplication | 2 * 3 | 6 |
/ | Division | 5 / 2 | 2.5 |
// | Integer Division (quotient) | 5 // 2 | 2 |
% | Modulo (remainder) | 5 % 4 | 1 |
^ | Exponent | 3 ^ 4 | 81 |
! | Factorial | 4! | 24 |
They evaluate the relationship between two values and return true or false. They are commonly used in formulas to compare numbers, text, or column values.
You can think of comparison operators like yes/no questions you ask about your data to evaluate relationships between values.
| Operator | Description | Example | Result |
|---|---|---|---|
| < | Less than | 5 < 10 | true |
| Greater than | 5 > 10 | false | |
| <= | Less than or equal to | 5 <= 5 | true |
>= | Greater than or equal to | 5 >= 6 | false |
| = | Equal | 5 = 5 | true |
| != | Not equal | 5 != 3 | true |
These operators evaluate conditions and return true/false or determine outcomes based on logic.
- Logical operators like
AND,OR, andNOThelp you build complex conditions by combining simpler ones. - Conditional operators like
CASEorIS NULLallow you to return specific values depending on which conditions are met.
You can think of logical operators as the building blocks of a test, and conditional expressions as the final decision maker.
| Operator | Description |
|---|---|
AND | Returns true if both conditions are true. Example: (5 > 3) AND (2 < 4) → true |
CASE WHEN ... THEN ... [ELSE ...] END | Returns the result corresponding to the first true condition. If no conditions are true, returns the ELSE result (if provided). Example: CASE WHEN 5 > 10 THEN 'High' WHEN 5 > 3 THEN 'Medium' ELSE 'Low' END → 'Medium' |
IS NOT NULL | Returns true if the value is not null. Example: 'abc' IS NOT NULL → true |
IS NULL | Returns true if the value is null. Example: NULL IS NULL → true |
NOT | Returns true if the condition is false, and false if the condition is true. Example: NOT(5 > 3) → false |
OR | Returns true if either condition is true. Example: (5 > 3) OR (2 > 4) → true |
Functions perform more advanced, often reusable operations. They take one or more inputs (called arguments) and return a calculated result.
Below is a categorized overview of available functions. Click a category below to jump to its detailed section.

Aggregate Functions

Date and Time Functions

Numeric Functions

Text Functions

Utility Functions

Window Functions
These perform calculations across multiple rows in a dataset, such as summing values or finding an average.
You can think of aggregate functions as "summary tools" — they look at all your data and give you a big-picture number.
| Syntax | Description |
|---|---|
AVG(expression) | Calculates the average (arithmetic mean) of all non-null values in expression across the dataset. Example: AVG([5, 10, 15]) → 10 |
COUNT(expression) | Counts the number of non-null values in expression across all rows. If expression is omitted, counts all rows. Example: COUNT(['A', 'B', null]) → 2 |
COUNTDISTINCT(expression) | Counts the number of unique (distinct) non-null values in expression across all rows. Example: COUNTDISTINCT(['A', 'B', 'A']) → 2 |
MAX(expression) | Returns the maximum value from expression across all rows. Example: MAX([10, 20, 5]) → 20 |
MEDIAN(expression) | Returns the median value from expression across all rows. Example: MEDIAN([1, 3, 5]) → 3 |
MIN(expression) | Returns the minimum value from expression across all rows. Example: MIN([10, 20, 5]) → 5 |
STDEV(expression) | Returns the sample standard deviation of values in expression across all rows. Example: STDEV([4, 6, 8]) → 2 |
STDEVP(expression) | Returns the population standard deviation of values in expression across all rows. Example: STDEVP([4, 6, 8]) → 1.63 (approx.) |
SUM(expression) | Returns the sum of all values in expression across the dataset. Example: SUM([5, 10, 15]) → 30 |
VARIANCE(expression) | Returns the sample variance of values in expression across all rows. Example: VARIANCE([4, 6, 8]) → 4 |
VARIANCEP(expression) | Returns the population variance of values in expression across all rows. Example: VARIANCEP([4, 6, 8]) → 2.67 (approx.) |
Used to extract parts of a date, perform date math, or return the current time.
These are your "calendar helpers" — they help you understand when things happen or calculate time-based differences.
| Syntax | Description |
|---|---|
DATEADD(date, number, interval) | Returns a new date by adding the specified number of interval units (e.g., 'day', 'month') to the given date. Example: DATEADD('2025-04-01', 7, 'day') → '2025-04-08' |
DATEDIFF(start_date, end_date, unit) | Returns the number of unit intervals (e.g., 'day', 'month') between start_date and end_date. Example: DATEDIFF('2025-01-01', '2025-01-10', 'day') → 9 |
DATEFORMAT(date, format) | Returns a text string representing the specified date in the given format. Example: DATEFORMAT('2025-04-15', '%b %-d, %Y') → Apr 15, 2025 |
DAY(date) | Returns the day of the month (1–31) from the given date. Example: DAY('2025-04-15') → 15 |
HOUR(date_time) | Returns the hour (0–23) from the given date_time. Example: HOUR('2025-04-15T14:30:00Z') → 14 |
MINUTE(date_time) | Returns the minute (0–59) from the given date_time. Example: MINUTE('2025-04-15T14:30:00Z') → 30 |
MONTH(date) | Returns the month (1–12) from the given date. Example: MONTH('2025-04-15') → 4 |
NOW() | Returns the current date and time in Coordinated Universal Time (UTC). Example: NOW() → '2025-04-23T10:42:00Z' |
QUARTER(date) | Returns the quarter (1–4) of the year for the given date. Example: QUARTER('2025-04-15') → 2 |
SECOND(date_time) | Returns the seconds (0–59) from the given date_time. Example: SECOND('2025-04-15T14:30:45Z') → 45 |
TODAY() | Returns the current date with time set to 00:00:00 in Coordinated Universal Time (UTC). Example: TODAY() → '2025-04-23' |
WEEK(date) | Returns the ISO week number (1–53) for the given date. Example: WEEK('2025-01-01') → 1 |
WEEKDAY(date) | Returns the day of the week (0 = Sunday, 6 = Saturday) for the given date. Example: WEEKDAY('2025-04-21') → 1 |
YEAR(date) | Returns the year from the given date. Example: YEAR('2025-04-15') → 2025 |
These apply mathematical formulas to one or more values.
Numeric functions are like a calculator inside your dataset — they help you transform and analyze numerical values.
| Syntax | Description |
|---|---|
ABS(number) | Returns the absolute (non-negative) value of number. Example: ABS(-5) → 5 |
CEILING(number) | Rounds number up to the nearest integer. Example: CEILING(4.2) → 5 |
FLOOR(number) | Rounds number down to the nearest integer. Example: FLOOR(4.8) → 4 |
MOD(dividend, divisor) | Returns the remainder after dividing dividend by divisor. Example: MOD(10, 3) → 1 |
POWER(number, exponent) | Returns number raised to the power of exponent. Example: POWER(2, 3) → 8 |
SQRT(number) | Returns the square root of number. Example: SQRT(9) → 3 |
Used to manipulate, transform, or extract information from text strings.
These are your "text editors" — perfect for cleaning up or formatting names, tags, and other string data.
| Syntax | Description |
|---|---|
CONCAT(value1, value2, ...) | Joins multiple values into a single string. Example: CONCAT('Data', 'box') → Databox |
CONTAINS(string, substring) | Returns 1 if the string contains the specified substring; otherwise, returns 0. Example: CONTAINS('dashboard', 'board') → 1 |
ENDSWITH(string, substring) | Returns 1 if the string ends with substring; otherwise, returns 0. Example: ENDSWITH('metrics.csv', '.csv') → 1 |
FIND(string, substring) | Returns the index of the first occurrence of substring in string. Returns 0 if not found. Example: FIND('dashboard', 'board') → 5 |
JSONEXTRACT(json_string, path) | Returns the fragment located at the specified JSONPath in the json_string. Example: JSONEXTRACT('{"user":{"id":123,"name":"Alice"}}', '$.user.id') → 123 |
LEFT(string, num_chars) | Returns the first num_chars characters from the string. Example: LEFT('Databox', 4) → Data |
LENGTH(string) | Returns the number of characters in the string. Example: LENGTH('Databox') → 7 |
LOWER(string) | Converts all characters in the string to lowercase. Example: LOWER('Databox') → databox |
REGEXEXTRACT(string, pattern, [group]) | Returns the specified match group (0-indexed) from the string, based on the regular expression pattern. If group is omitted, it defaults to 0. Example: REGEXEXTRACT('databox.com', '([a-z]+)\.com') → databox |
REGEXREPLACE(string, pattern, new_substring) | Returns string with all text matching the regular expression pattern replaced by new_substring. Example: REGEXREPLACE('abc123def', '([0-9]+)', 'X') → abcXdef |
REPLACE(string, old_substring, new_substring) | Replaces all occurrences of old_substring in the string with new_substring. Example: REPLACE('2025-05-01', '-', '/') → 2025/05/01 |
RIGHT(string, num_chars) | Returns the last num_chars characters from the string. Example: RIGHT('Databox', 3) → box |
SPLITROWS(string, separator) | Returns one row for each value in the string, split by the specified separator. Example: SPLITROWS('a;b;c', ';') → ['a', 'b', 'c'] |
STARTSWITH(string, substring) | Returns 1 if the string starts with substring; otherwise, returns 0. Example: STARTSWITH('dashboard', 'dash') → 1 |
SUBSTRING(string, start, [length]) | Extracts a substring from the string starting at the start index, with an optional length. Example: SUBSTRING('Databox', 5, 3) → box |
TRIM(string) | Removes whitespace from the beginning and end of the string. Example: TRIM(' Databox ') → Databox |
UPPER(string) | Converts all characters in the string to uppercase. Example: UPPER('Databox') → DATABOX |
Versatile functions for comparisons, conditionals, and handling nulls or arrays.
Utility functions are the "everyday helpers" — they let you apply simple if-then logic, set fallbacks for nulls, compare values to find minimums or maximums, or expand arrays into individual rows.
| Syntax | Description |
|---|---|
COALESCE(value1, value2, ...) | Returns the first non-null value from the list. If all values are NULL, the result is NULL. Example: COALESCE(NULL, 'default', NULL, 'other') → default |
GREATEST(value1, value2, ...) | Returns the largest value from a list of numbers, strings, or other comparable values. NULL values are ignored unless all values are NULL, in which case the result is NULL. Example: GREATEST(10, 5, 20) → 20 |
IF(condition, true_value, false_value) | Returns true_value if condition is true; otherwise, returns false_value. Example: IF(5 > 3, 'Yes', 'No') → Yes |
IFNULL(expression, value_if_null) | Returns expression if it is not NULL; otherwise, returns value_if_null. Example: IFNULL(null, 'N/A') → N/A |
LEAST(value1, value2, ...) | Returns the smallest value from a list of numbers, text values, or other comparable values. NULL values are ignored unless all values are NULL, in which case the result is NULL. Example: LEAST(10, 5, 20) → 5 |
UNNEST(array_expression) | Returns each element of array_expressionas a separate row. Often paired with JSONEXTRACT to expand extracted arrays into individual rows. Example: UNNEST('["tech","science","art"]') → ['tech','science','art'] |
Functions for row numbering, ranking, and accessing values across partitions.
Window functions are the "look across rows" tools — they let you assign sequence numbers, compare values within groups, or pull data from preceding or following rows.
| Syntax | Description |
|---|---|
FIRSTVALUE(column_expression, order_columns, [partition_columns]) | Returns the first value of the specified column or expression, based on the defined sort order. If partition_columns columns are provided, returns the first value within each group. Sort direction defaults to ascending (ASC) if not specified. Example: FIRSTVALUE($customer_email, '$order_date, $total_amount DESC', '$store_id, $customer_id') → Returns the first email address associated with each customer in each store, based on order date (earliest first) and total amount (highest first). |
LAG(column_expression, order_columns, [partition_columns], [offset], [default_value]) | Returns a value from a previous row in the sorted data. If partition_columns are provided, looks back within each group. If offset is not specified, returns the value from the previous row. If no value exists (for example, it's the first row in the group), returns NULL or the default_value. Sort direction defaults to ascending (ASC) if not specified. Example: LAG($balance, '$transaction_date', '$account_id', 1, 0)→ Returns the previous balance for each account, based on transaction date. If it's the first transaction, returns 0 |
LASTVALUE(column_expression, order_columns, [partition_columns]) | Returns the last value of the specified column or expression, based on the defined sort order. If partition_columns are provided, returns the last value within each group. Sort direction defaults to ascending (ASC) if not specified. Example: LASTVALUE($customer_email, '$order_date, $total_amount DESC', '$store_id, $customer_id')→ Returns the last email address associated with each customer in each store, based on order date (earliest first) and total amount (highest first). |
LEAD(column_expression, order_columns, [partition_columns], [offset], [default_value]) | Returns the value of a column or expression from a later row in the sorted result. If partition_columns are provided, looks ahead within each group. If no offset is specified, the function defaults to the next row. If no value exists (e.g. it's the last row), returns NULL or the specified default_value. Sort direction defaults to ascending (ASC) if not specified. Example: LEAD($order_date, '$order_date ASC', '$customer_id', 1, NOW()) → Returns the date of the next order for each customer. If no future order exists, returns the current date and time. |
ROWNUMBER([order_columns], [partition_columns]) | Assigns a sequential number starting from 1 to each row. If order_columns are provided, rows are numbered based on the specified sort order. If partition_columns are provided, numbering restarts within each group. Sort direction defaults to ascending (ASC) if not specified. Example: ROWNUMBER('$order_date, $total_amount DESC', '$store_id, $customer_id') → Sorts orders by date (ascending) and total amount (descending), and assigns a row number for each customer in each store, starting from 1. |
FAQ
Can I reference multiple columns in the same formula?
Yes. You can include as many column references as needed by using the $ symbol before each column name (e.g., $Revenue - $Cost).
Can I use the calculated column to create custom metrics?
Absolutely. Once saved, calculated columns behave like any other column in your dataset and can be used in metric creation.
Will the calculated column update automatically if the source data changes?
Yes. The calculated column is dynamic — it will recalculate automatically whenever the underlying dataset is refreshed.



